Why Spun Content that Passed Copyscape is Still Bad

 ContentPowered.com
ContentPowered.com
Blogging is hard. It’s so hard that thousands of bloggers try to take a shortcut in some way. You know what? It never, never works. Google is a billion dollar company with some of the brightest engineers working around the clock to prevent low quality content from surfacing and aggravating it’s users. Your cheap content spinning software certainly won’t fool them.
- When was the last time you saw a highly-ranked blog with a lot of traffic and monetization, hosted on a free web host?
- When was the last time you saw someone making loads of money from one of those thin affiliate sites?
- When was the last time you did a Google search and game up with five iterations of the same content, clearly spun from one to the next?
None of those techniques ever work, and yet there are hordes of black hat webmasters trying and trying to game the process, to put these loopholes into action. They convince themselves in their self-delusion that their means may be sketchy, but their results are worth it.
Meanwhile, the legitimate bloggers are laughing and enjoying their positions at the top. They didn’t need to spin articles, they didn’t need to dive into weird link schemes; they just worked hard and succeeded where others failed.
The ultimate irony is that so many of these black hat marketers put more work into their repeat failures than the actual legitimate techniques would take. It’s not that much effort to forge a relationship with a few ghostwriters, particularly not compared to the constant hunt for an article spinner that doesn’t suck and isn’t circumvented by Google.
I’m not here to convince you not to use article spinners. If you need convincing, you aren’t going to listen to reason. I’m just writing this because it lets me laugh at the black hats that willfully ignore the thousands of step by step articles that could lead them to success, and instead believe that This Mom’s One Weird Trick will get them to the top. Google hates her!
I mean, really. When even those kids at Black Hat World tell someone not to use spun content, you’d think the concept would finally die, but no.
What is Copyscape
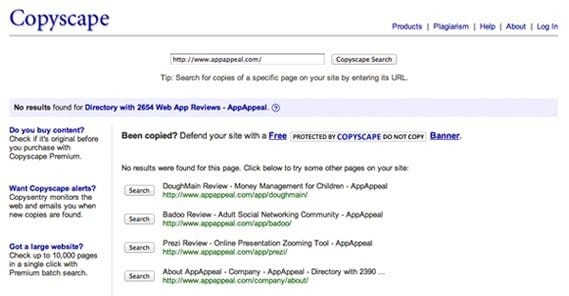
The title of this article throws two terms at you that you may not know. One of them is Copyscape, and one of them is spun content. I’ll explain each in turn.
Copyscape is this website. Essentially, it scans the Internet and indexes the content it finds, in much the same way that Google does. It’s made to be a plagiarism checker, initially for use in academic circles, to check to see if a student’s paper has been copied from some third party source. Academic plagiarism is a big deal, particularly in graduate school, where a term paper makes or breaks your entire career.
When Google debuted the Panda algorithm change in 2011, it shook up the internet world. Previously, one of the best ways to get a highly ranked site was to create a ton of content, laced with keywords, to rank you for every topic you could find. It’s why giant sites like Gawker Media, eHow, Livestrong, and all the other Demand Media properties existed. It’s why EZineArticles and Squidoo and all the rest were based on volumes of content. They didn’t care what you published; as long as you published a lot, you earned them a lot in revenue share, and they would graciously split some of it with you. Or, you tried the same thing with a site of your own, and pocketed the money yourself.
Panda changed all that. Overnight, sites like BrightHub lost 95% of their visibility and traffic. It was downright apocalyptic for some sites, which died off and have never recovered. Others, like the previously mentioned eHow, continually monitor the bare minimum they have to do for success, and raise their standards to just that level and no higher. It’s a constant race, and one that is much easier on Google than eHow, but such is the nature of the game.
What does this have to do with Copyscape? One of the main ways some of these sites would get huge volumes of content in the past was to take articles other people had written and spin them. Panda made this a punishable offense, and put a much, much greater emphasis on the uniqueness of a piece of content.
That’s where Copyscape came in. People realized that a broad-indexed plagiarism checker was ideal for checking to see if a piece of content was unique. Webmasters used it when they bought content, to protect themselves. And, most importantly, webmasters decided that if a piece of content could pass Copyscape, it could pass Google’s inspection as well. Is that true? We’ll get to that later.
What are Article Spinners
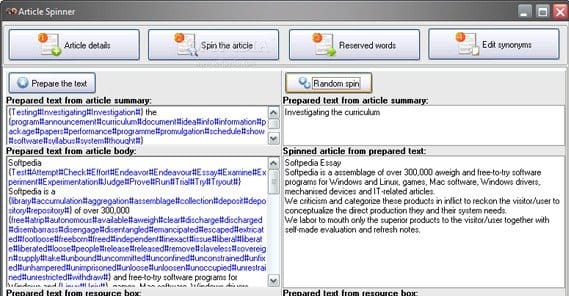
The other term I threw at you in the beginning is the concept of spun content. The essential core of spun content is taking one piece of content and swapping out words to create another piece of content, with the same meaning, but enough uniqueness that it reads like a unique piece of content. For example:
- These red tennis shoes are great for traction in the rain.
- These crimson sneakers are excellent for grip in wet conditions.
Those two sentences are identical in meaning, but they are unique in terms of words used.
Article spinning revolves around the division between three types of words. You have your content words, which can be swapped out with synonyms to create a new sentence. Tennis shoes and sneakers is one example. You also have your stop words, which are words like these, are, for, and in. These words don’t matter; Google, Copyscape and all the rest ignore them, because you can’t really flag a piece of content as copied based on the repeated use of such common and grammatically-integral words.
The third type of word is the keyword, which typically isn’t changed when spun, to maintain the focus and SEO of a piece of content. Of course, the actual SEO value of a piece of content has a lot more to do with context, trust, and links than it does on the content itself, but that’s a detail spun content advocates seem to miss.
There are a few different levels of article spinning.
- Mechanically spun. This is content run through a bot that swaps out synonyms and spits out spun content. It’s not very good, it’s easy to detect, and it’s likely to replace words in a poor manner.
- Multi-spun. This is mechanical spinning that takes the output and feeds it through the algorithm again, sometimes multiple times, to create something that is several degrees removed from the initial submission.
- Mechano-manual spun. This is when the article is spun with a machine, but given a once-over by a writer to fix some of the more glaring issues or to spin hard-to-adapt sentences. It’s aimed at fixing the issues with article spinning, but falls flat.
- Manual spun. This is when no software or robot is involved at all; a writer with a large vocabulary or access to thesaurus.com is all that’s necessary. At this point, you’re paying a writer to do the work for you, so why not just pay for unique content instead?
All levels of spinning have flaws. They’re either easy to detect, read like shit, or are more expensive than just producing legitimate content in the first place.
The Major Flaws in the Spin Plan

The big selling point most article spinners advertise is “Copyscape passed.” In other words, the machine algorithm in Copyscape doesn’t see enough similarity between the output of the spinner and anything in its index to flag it as copied. Webmasters assume for some reason that this means it passes Google, when Google is infinitely more sophisticated. Let’s take a look at all the flaws, shall we?
 How Do Free Traffic Generator Programs Work? For decades, webmasters have been trying every…
How Do Free Traffic Generator Programs Work? For decades, webmasters have been trying every…

Google knows how spinners work. For one thing, they’re not exactly very sophisticated pieces of software. If a casual reader can tell when a piece of content is spun, so can someone actually looking out for spun content.
Plus, you didn’t think Google is some high and mighty god with no view of the little people, did you? There’s absolutely nothing stopping Google from buying a copy of any article spinner on the market and immediately reverse-engineering it to figure out how it works. Once that happens, it’s game over for the current version of that spinner. Then when that spinner updates to function once Google has adapted, they send out messages to subscribers to get them to update, and Google gets one of those notices too. How could you possibly win in that situation?
I saw one article spinner that advertised “spinning stop words” as its means to success. It keeps the rest of the language, including keywords, the same. Now, I don’t know about you, but if I see two sentences and the only change is pluralization, it’s pretty damn obvious what happened there. Plus, Google even knows to ignore stop words when analyzing content! They might as well not exist, and that makes the spinner utterly useless.
The fight is always on. There’s a constant battle between black hats and Google. It’s no different from the fight between antivirus programs and virus creators, or between hackers and security companies. In some arenas it may seem like the black hats are winning, but not in this one.
People can recognize when a post is written poorly. This is, really, the biggest single killer of article spinners ever. People have an innate sense of what is and isn’t proper English, and article spinners trip that sense. There’s no mechanical spinner in the universe good enough to create unique content. There just isn’t. Some news articles have even been written by machines in an attempt to prove how indistinguishable machine-written content is, but they always fall flat. Until we create a real, working artificial intelligence, you won’t be able to make indistinguishable spun content.
I should hope that, if we do create AIs, we don’t put them into content-creation slavery. If we do, well, I’m going to side with Skynet.
Uniqueness doesn’t mean value. This is a big piece of the Google algorithm that black hat spammers tend to miss. See, spun content has to come from somewhere. You have a piece of content that already exists, and thus is already indexed and ranked. You spin that content, and publish it. Now what?
The new content is newer than the old content. That means the older content has an SEO advantage. The new content is poorly spun, which makes it harder to read than the old content, another SEO hit. The spun content is put on a website that doesn’t have a lot of trust built up, giving it yet another hit. You can go on and on with these comparisons.
Unless you’re stealing content from deindexed sites to use in your indexed site, chances are the original content is going to out-rank your spun copy any day of the week. You’re never going to out-rank original content, no matter how much you spin it. The reason is simple; to unseat a champion in search, you need to do what they do, only better. If you can’t one-up their content, you can’t unseat it, and you can’t surpass it.

Synonyms have different meanings. This is another damning flaw with spun content. It relies on a thesaurus or a dictionary to swap out words, but it’s purely mechanical with an element of randomness. Take these two sentences, for example.
- Sylvester is a popular author with a large body of work available for purchase.
- Sylvester is a prominent writer with a big corpse of effort accessible for buying.
Which one of those is spun? The second one, right? How could you tell? Oh, let me count the ways.
- Prominent doesn’t necessarily mean popular, just large in the field.
- The word big is used in an amateurish way.
- Body and corpse may be synonyms in one sense, but very much not in this sence.
- Work in the physics sense does mean effort, but it’s not the right word choice here.
- Buying is a misplaced form of the word as a replacement for purchase, and changes the grammatical structure of the sentence in a negative way.
Now imagine that your entire blog is filled with posts that are spun. That sentence has five flaws, and it’s only 14 words long. Now extend that to a 1,000 word blog post, and multiple it times 5 posts a week for however long you like. How many thousands of mistakes exist on that site?
Trick question; it doesn’t matter, because no one bothers reading past the opening paragraph of the first post they see. If they’re smart, they’ll even blacklist the site so it doesn’t show up in their results again.
At best, the content looks like it was written by someone who speaks English as a second language. At worst, it’s near-gibberish that isn’t passable from a mile away.
I have nothing against ESL speakers. There’s a certain character to their blogs that takes the form of odd and unique turns of phrase, but the content is still readable. More importantly, there’s value to their content. This is clear in the SEO and internet marketing field above most others, simply because there are so many people of Indian or Middle Eastern descent writing in the field.
I’d use Neil Patel as an example here, but there are two flaws with that. First, his writing isn’t ESL. Second, he was born in London, so he really doesn’t fit the criteria. It’d be stereotypical to think he would, actually.
Just Hire a Writer

At the end of the day, this is what it comes down to. Article spinners are a pipe dream for black hats who want an easy way past all of the work bloggers have to put in to run a successful blog. The best way to spin an article is to do it manually, and that requires a writer. At that point, it’s incredibly simple to just say “use this article as a source and expand upon it.”
There. It’s that easy. Done. The writer will produce for you a piece of content that is unique, valuable, and more useful than the original. This, for the same money you would pay a writer to spin content for you, or to edit your poorly spun content before publication. It eliminates every one of the problems that comes from spinning, and for the same cost.
Besides, have you seen the cost of article spinners recently? They may be cheap individually, but how long will you use a spinner before you realize it isn’t working? You’ll shop around for another, and go through the same process, time and again, practically on a monthly basis. It adds up, is all I’m saying.
Don’t spin articles. It’s dumb, it’s valueless, and it’s wasted effort.



The problem happens when a big company pay good money to good writers to spin your original content . And with a fast website and a team of engineers , original publishers get crushed in search..